Structuring mechine learning projects¶
You have a lot of ideas for how to improve the accuracy of your deep learning systems:
- Collect more data;
- Collect more diverse training set;
- Train algorithm longer with gradient descent;
- Try different optimization algorithm(e.g. Adam);
- Try bigger network;
- Try smaller network;
- Try drop out;
- Add L2 regularization;
- Change network architecture(activation functions, number of hidden units, etc.).
This chapter will give you some strategies to help analyze your problem to go in a direction that will help you get better result.
Orthogonalization¶
Some deep learning developers know exactly what hyperparameter to tune to try to achieve one effect. This is a process we call orthogonalization. In orthogonalization, you have some controls, but each control does a specific task and doesn't affect other controls.
For a supervised learning system to do well, you usually need to tune the knobs of your system to make sure that four things hold true:
- You'll have to fit trainning set well on cost function(near human level performance if posiible);
- Fit dev set well on cost function;
- Fit test set well on cost function;
- Performs well in real world.
Single number evaluation metric¶
It's better and faster to set a single number evaluation metric for your project before you start i.
Precision and recall¶
Suppose we run the classifier on 10 images which are 5 cats and 5 non-cats. The classifier idetifies that there are 4 cats, but it identified 1 wrong cat. The confusion matrix is:
| iterm | Predicted cat | Predicted non-cat |
|---|---|---|
| Actual cat | 3 | 2 |
| Actual non-cat | 1 | 4 |
The
Precision: perception of true cats in the recognized result: \(P = \frac{3}{3+1}\);Recall: perception of the true recognition cats of the all cat predictions: \(R = \frac{3}{3+2}\);Accuracy: \(A = \frac{3 + 4}{10}\).
Using a precision/recall for evaluation is good in a lot of cases, but separately they don't tell you which algorithm is better. A better idea is to combine precision and recall in one single number evaluation metric called F1:
Sometimes it's hard to get a single number evaluation metrix, ex:
| Classifier | F1 | Running time |
|---|---|---|
| A | 90% | 80ms |
| B | 92% | 95ms |
| C | 92% | 1500ms |
So we can solve this problem by choosing a single optimizing metric and set that other metrics are satisfying, ex:
| Metric type | Metric |
|---|---|
| optimizing metric | Maximizing F1 |
| satisfying metric | running time < 100ms |
The general rule is:
- Set \(1\) optimizing metric;
- Set \(N-1\) satisfying metric.
Train/dev/test distributions¶
- Dev and test sets have to come from the same distribution;
- Choose dev set and test set to reflect data you expect to get in the future and consider important to do well on;
- Setting up the dev set as well as the validation metric really depends on what target you want to aim at.
Size of the dev and test sets¶
- The old way(number < 100000) of splitting the data was 70% training, 30% test or 60% training, 20% dev, 20% test;
- If you have more data, a reasonable split would be 98% training, 1% dev, 1% set.
Human level performance¶
We compare to human-level performance because of two main reason:
- Because of advances in deep learning, machine learning algorithms are suddenly working much better and so it has become much more feasible in a lot of application areas for machine learning algorithms to actually become competitive with human-level performance.
- It turns out that the workflow of designing and building a machine learning system is much more efficient when you're trying to do something that humans can also do.
After an algorithm reaches the human-level performance the progress and accuracy slow down.
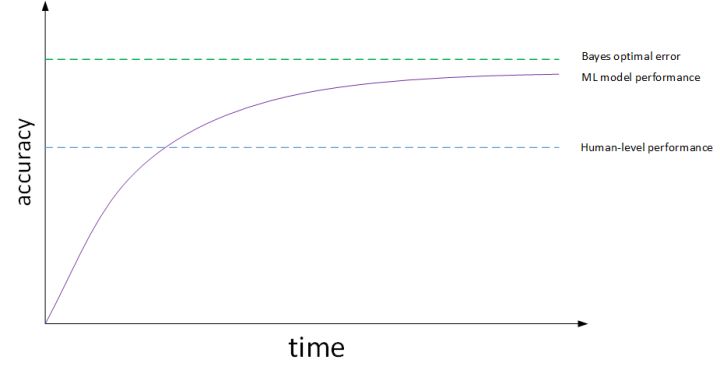
You won't surpass an error called "Bayes optimal error", and there isn't much error range between human-level error and Bayes optimal error. Humans are good at a lot of tasks. So as long as Mechine learning error is worse than human's, you can:
- Get labeled data from humans;
- Gain insight from manual error analysis: why did a person get it right?
- Better analysis of bias/variance.
Avoidable bias¶
Suppose that the cat classification algorithm gives these results:
| Humans | 1% | 7.5% |
|---|---|---|
| Trainning error | 8% | 8% |
| Dev error | 10% | 10% |
In the left example, we have to focus on the bias because the human level error is 1%;
in the right example, we have to focus on the variance because the human level error is 7.5%.
The human-level error is a proxy for Bayes optimal error, Bayes optimal error is always less, but human-level in most case is not far from it. You can't do better than Bayes error unless you are overfitting.
Avoidable bias = Traning error - Human(Bayes) errorVariance = Dev error - Trainning error
Having an estimate of human-level performance gives you an estimate of Bayes error, this allows you to more quickly make decision which error you should focus to reduce:
- If
avoidable biasdifference is the bigger, then it's abiasproblem, and you should use a strategy forbiasresolving; - If
variancedifference is bigger, then you should use a strategy forvarianceresolving.
Improving your model performance¶
There are two fundamental assumptions of supervised learning:
- You can fit the training set pretty well, this is roughly saying that you can achieve
low avoidable bias. - The training set performance generalizes pretty well to the dev/test set. This is roughly saying that the
varianceis not too bad.
Depends on the error difference, we have following guidelines:
- If
avoidable biasis large, you can:- Train bigger model;
- Train longer/better optimization algorithm(e.g. Momentum, RMSprop, Adam);
- Find better neural network architecture or hyperparameters.
- If
varianceis large you can:- Get more training data;
- Regularization(L2, Dropout, data augmentation);
- Find better neural network architecture or hyperparameters.
Carrying out error analysis¶
Error analysis is the process of manually examining mistakes that your algorihtm is making. It can give you insights into what you should do next. For example, if you have 10% error on your dev set and you want to decrease error. You discovered that some of the mislabled data are dog pictures that look like cats, you should:
- Get 100 mislabeled dev set examples at random;
- Count up how many are dogs.
- Check the result:
- If 5 of 100 are dogs, then training your classifier to do better on dogs will decrease your error up to 9.5%, which means it may not worth it.
- If 50 of 100 are dogs, then you could decrease your error up to 5%, which is reasonable and you should work on that.
Sometimes you can evaluate multiple error analysis ideas in parallel and choose the best idea:
| Image | Dot | Great Cats | Blurry | Instagram Filters | Comments |
|---|---|---|---|---|---|
| 1 | Y | Y | Pitbull | ||
| 2 | Y | Y | Y | ||
| 3 | Rainy day at zoo | ||||
| 4 | Y | ||||
| ... | |||||
| total |